Aditya Raj
I am a final-year B.Tech student at NIT Patna, graduating in 2026 with a major in Electronics and Communication Engineering.
My interest in memory mechanisms developed during my Summer 2025 internship at IIIT-H, where I was fortunate to work on retrieval systems under the guidance of Dr. Kuldeep Kurte. This experience oriented my interest in memory systems for AI. My future of AI is "white-box": a personal collaborative assistant that empower humans, rather than replacing them.

Research
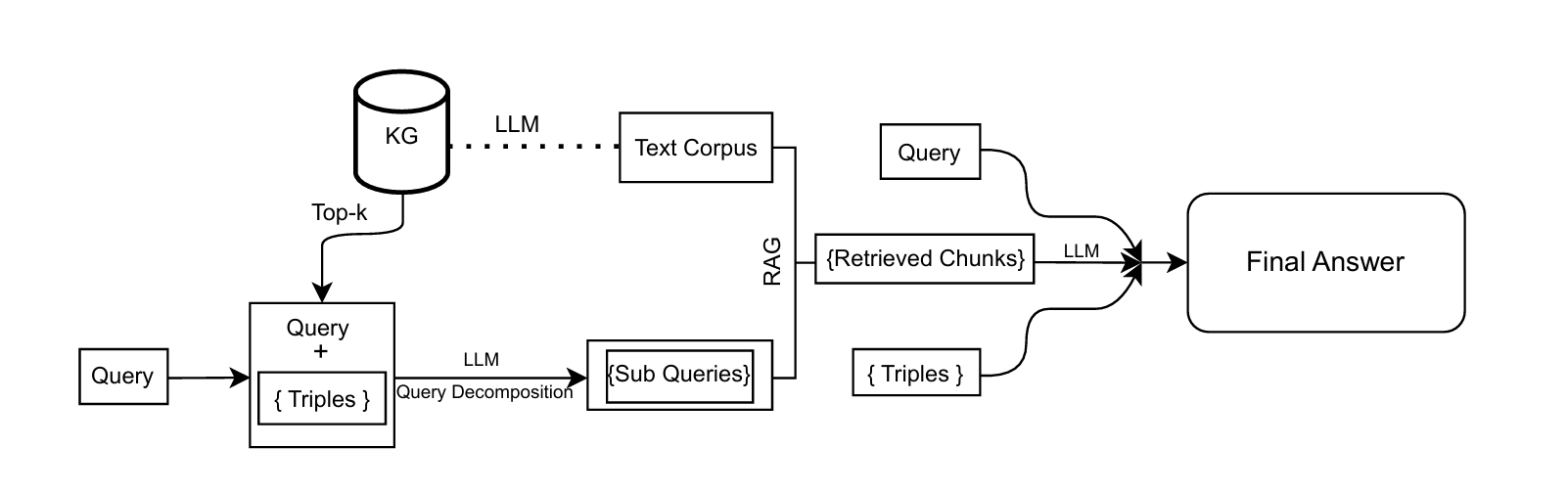
Knowledge Graph-Informed Query Decomposition (KG-IQD): Hybrid KG-RAG Reasoning in Noisy Context
Aditya Raj1, Kuldeep Kurte2
1National Institute of Technology, Patna, 2IIIT Hyderabad
Achieved state-of-the-art results on a custom disaster QA benchmark, outperforming RQ-RAG by 14% and KG by 18%. Developed a neuro-symbolic framework for query decomposition, leveraging knowledge graphs to interrelate points for hybrid RAG-based reasoning over structured and unstructured data.
Achievements
Experience
Quant Developer Intern @ QFI Research Capital
Hyderabad, India
May 2025 – July 2025
Research Intern @ IIIT HyderabadISWC 2025 (In Review)
Hyderabad, India | Advisor: Dr. Kuldeep Kurte, Spatial Informatics Lab
Apr 2025 – July 2025
Research Intern @ IIT Guwahati
Guwahati, India | Advisor: Dr. Arijit Sur, Mentor: Mr. Suklav Ghosh
June 2024 – July 2024
Projects
IV Prediction - Indian Option Market
July 2025 – July 2025
July 2025 – July 2025
Engineered a LightGBM pipeline that achieved an MSE of 1.3e-5 on sparse options data, utilizing nearest-neighbor TTE estimation and call/put-specific data representation.
Replaced a $150/month SaaS solution by building a serverless platform that migrated 10,000+ users. Achieved <1s LCP on slow 4G networks using a Next.js/Vercel/Supabase stack with extensive frontend optimizations.
Multimodal-Reranker
Mar 2025 – Apr 2025
Mar 2025 – Apr 2025
Engineered a multimodal reranking module for an AI search engine, leveraging Ollama LLM for semantic filtering and JSON filter extraction from natural queries, combined with vision-language models and a fast FAISS (HNSW+IVF) retriever on CLIP/mxbai embeddings, reranking top-k results via cosine for refined search based on user intent and visual semantics.
Engineered an OCR pipeline for medieval-era handwritten Spanish manuscripts by combining TrOCR for initial transcription with a T5-based language model for post-correction, fine-tuned on domain-specific linguistic features. Designed and integrated a custom text augmentation and similarity-preserving algorithm to enhance LM robustness; achieved a Word Error Rate (WER) of 0.116, outperforming all competing models.